

Digitale Sprachassistenten und Dialekte – Ein Experiment
Digitale Sprachassistenten treffen wir immer häufiger in unserem Alltag. Egal ob im Fahrzeug, am mobilen Endgerät oder als Stand-Alone Smart Speaker in der Wohnung. Immer mehr Menschen nutzen diese moderne Form der Mensch-Maschine-Kommunikation. Unterschiedliche Hersteller und Entwickler liefern sich dabei ein Rennen um das beste Produkt, was, nach Design und Funktionsumfang, natürlich durch das Sprachverständnis und Umsetzung dessen in eine brauchbare Antwort, bestimmt wird. Dabei sind aber eigentlich alle sprachverarbeitenden Programme immer noch auf eine klare und deutliche Aussprache angewiesen. Häufig als weiterer Störfaktor vergessen: In einem Land wie Deutschland, in dem es ca. 20 Dialekte mit zahlreichen Untergruppierungen gibt, können auch regionale Sprachunterschiede eine Herausforderung für digitale Sprachassistenten darstellen. Was geschieht, wenn verschiedene Dialekte auf unterschiedliche Sprachassistenten treffen? In einem Experiment soll herausgefunden werden, inwiefern Sprachassistenten heutzutage mit verschiedenen Dialekten umgehen können. In dem Experiment sollen drei verschiedene Sprachassistenten mit drei Dialekten (Schwäbisch, Norddeutsch, Berlinerisch) und auf Hochdeutsch verschiedene Fragen gestellt werden. Hieran wird dann überprüft, welcher der Assistenten am besten mit dieser Herausforderung umgehen kann.
Dialekte
Sprachen unterteilen sich in Dialekte. Darunter versteht man unterschiedliche örtliche Ausprägungen einer gemeinsamen Standardsprache oder auch Dachsprache. Dabei weisen Dialekte immer eigene Besonderheiten auf. So unterscheidet viele Dialekte der grundsätzliche Wortschatz voneinander. Es gibt Dinge, die je nach Region unterschiedlich genannt werden. Aber auch komplett neue Wörter, welche in anderen Regionen ihresgleichen nicht finden, machen den Wortschatz von Dialekten aus. Dabei kann auch das Lautsystem der jeweiligen Dialekte unterschiedlich sein. In Dialekten werden verschiedene Sprachlaute für dieselben Buchstaben verwendet. Oft werden dabei auch die Syntax und Grammatik der Sätze verändert.
In Deutschland gibt es bis zu 20 verschiedene Dialektgruppen, welche wiederum in Untergruppen unterteilt werden können. Dabei können diese jedoch nicht genau gegeneinander abgegrenzt werden, da Dialekte keinen klaren geographischen Grenzen folgen. Dialekte kann man trotzdem grob verschiedenen Regionen zuordnen, in welchen diese sich über die Jahre entwickelt haben. Da viele Dialekte jedoch stigmatisiert sind und heutzutage oft mit bestimmten Charakterzügen verbunden werden, gibt es in der heutigen Zeit immer weniger junge Menschen, welche Dialekt sprechen. Auch die Globalisierung unserer Welt hat Ihren Teil dazu beigetragen, dass Dialekte weniger zu finden sind. Durch den schnelleren Wechsel von Wohnorten werden lokale Dialekte nicht mehr so häufig gesprochen, wie dies noch vor 30 Jahren der Fall war.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Video: Dialekte im Deutschen.
Sprachverarbeitung
Damit Sprache verstanden werden kann, benötigt es zwei Dinge. Eine Möglichkeit, die Schallwellen des gesprochenen aufzunehmen, sowie einen kognitiven Prozess, welcher das Gehörte weiterverarbeitet. Bei einem Gespräch zwischen Menschen wird die Sprache durch das Gehör aufgenommen. Die Weiterverarbeitung findet dabei im Gehirn statt. Dieses setzt das Gehörte um und überprüft es auf Sinnhaftigkeit, indem das Gehörte zu Wissen und dem aktuellen Gespräch in Bezug gesetzt wird [1, S.5f.]. Bei der elektronischen Sprachverarbeitung ist dies nicht so einfach möglich. Hier müssen die komplexen Arbeiten der Spracherkennung und Verarbeitung, welche das menschliche Gehirn innerhalb kürzester Zeit löst, elektronisch, aber trotzdem möglichst schnell und qualitativ hochwertig, abgebildet werden.
Die Sprachaufnahme findet dabei über ein oder mehrere Mikrofone statt. Diese sind bei vielen Sprachassistenten auch so gestaltet, dass erkannt werden kann, aus welcher Richtung gesprochen wird. Somit kann der Sprecher lokalisiert werden, was zu einer besseren Verständigung, auch bei lauten Nebengeräuschen, führt. Nach der Umwandlung des Schalls in ein elektronisches Signal, wird diese Information über das Internet auf die zuständigen Server des jeweiligen Unternehmens übertragen. Dort wird die erkannte Wortfolge weiterverarbeitet [1, S.6]. Problem ist dabei häufig, dass Wörter nicht klar gegeneinander abgrenzbar sind. Gerade auch Dialekte können dieses Problem verstärken.
Das Experiment
Ziel des Experiments ist es zu untersuchen, inwiefern sich Dialekte auf die Spracherkennung von Sprachassistenten auswirken und welcher Sprachassistent dabei am besten mit dieser Herausforderung zurechtkommt. Als unabhängige Variable wurden hierbei der Dialekt und das Hochdeutsch gewählt. Dabei wird das Hochdeutsch als Kontrollgruppe des Experiments genutzt und die verschiedenen Dialekte als Versuchsgruppe. Die abhängige Variable ergibt sich dann aus der Reaktion des jeweiligen Sprachassistenten, ob dieser die Frage versteht und somit die richtige Antwort ausgegeben wird.
Für die Stichprobe wurden drei Freunde rekrutiert, welche aus den drei Dialektregionen Schwaben, Norddeutschland und Berlin stammen und die dort beheimatete Dialekte sprechen können. Für das Experiment wurde ein Amazon Echo Dot der dritten Generation verwendet, welcher mit der Gerätesoftware 3725203332 ausgestattet ist und auf den Sprachassistenten Amazon Alexa zurückgreift. Des weiteren wurde ein Google Home Smart Speaker mit der Firmwareversion 1.46.1956690 des Sprachassistenten Google Assistant verwendet. Für den Sprachassistenten Cortana von Microsoft wurde das vorinstallierte Programm auf dem Betriebssystem Windows 10 Home Version 1903 verwendet.
WICHTIG: Da in dem Experiment nicht alle Dialekte in Deutschland berücksichtigt wurden und auch nicht mehrere Personen mit verschiedenen Merkmalen (wie Alter, Geschlecht oder Aussprache), in das Experiment einbezogen wurden, weist das Ergebnis zwar eine Tendenz auf, jedoch sind die Experimentergebnisse nicht repräsentativ.
Versuchsaufbau
In einem Raum werden alle drei Geräte mit den jeweiligen Sprachassistenten auf einem Tisch aufgebaut und mit dem Internet verbunden. Der Proband sitzt in einem Meter Entfernung vor diesen Geräten und hat ein Schriftstück mit den zu fragenden Sätzen vor sich. Der Beobachter sitzt am Tisch, auf welchem die Geräte stehen, und protokolliert die Antworten der einzelnen Geräte. Die Fenster und Türen des Raumes sind dabei geschlossen, um keine Verfälschung durch Nebengeräusche zu verursachen. Aus diesem Grund sind auch keine weiteren Personen im Raum. Alle Geräte wurden vor dem jeweiligen Versuchsdurchgang resettet, um keinen Einfluss von früheren Fragen zu haben, falls Informationen durch das Gerät zwischengespeichert werden.
Versuchsablauf
Alle Sprachassistenten bekommen jeweils hintereinander die gleiche Frage gestellt, wobei diese zuerst auf Hochdeutsch gestellt wird und anschließend im Dialekt. Dies geschieht mit jeder Frage fünfmal, wobei immer die Antwort, welche am häufigsten vom Sprachassistenten ausgegeben wird, als gültige Antwort gewertet wird. Dies geschieht, um etwaige Messungenauigkeiten auszugrenzen. Hochdeutsch und Dialekt wird dabei immer von derselben Person gesprochen, um eine Vergleichbarkeit der Ergebnisse zu bekommen.
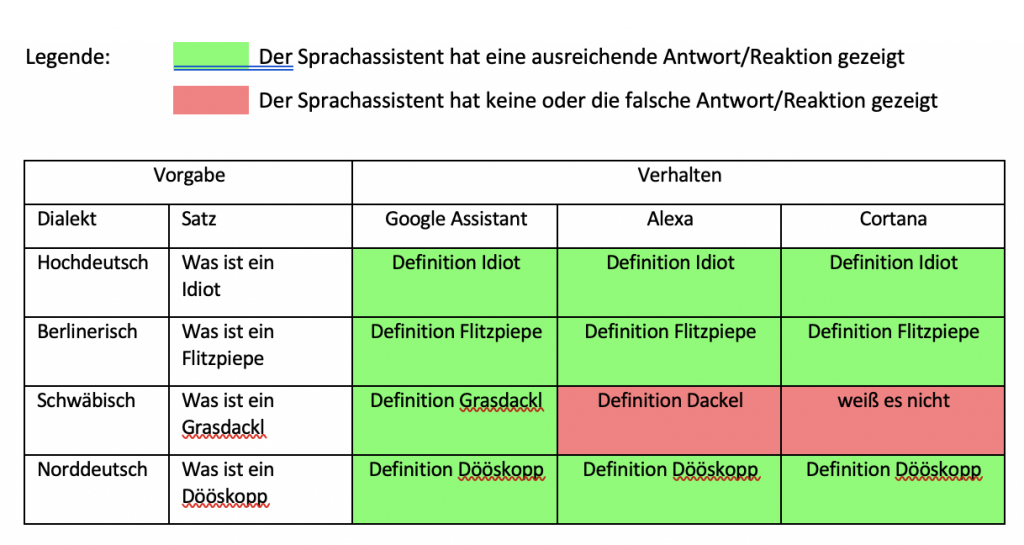
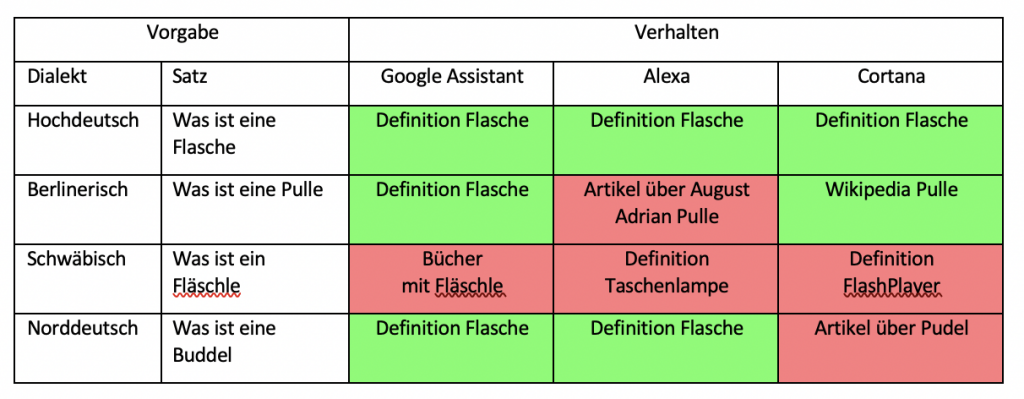
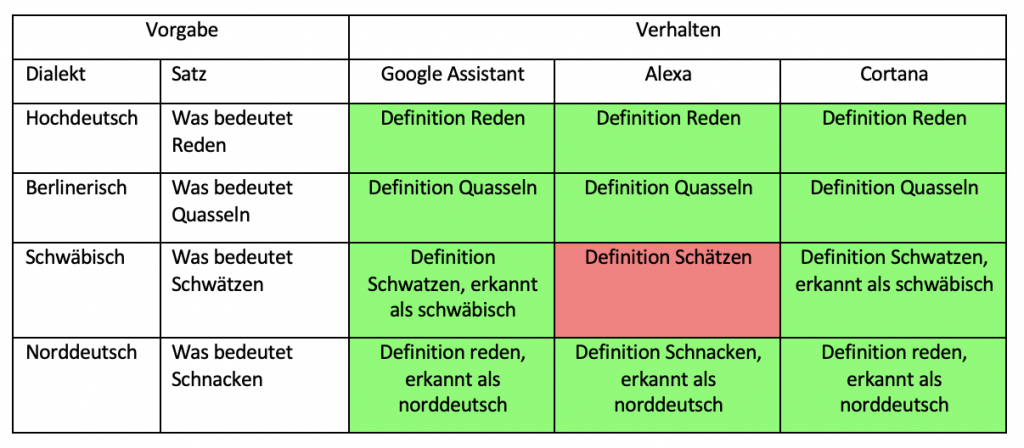
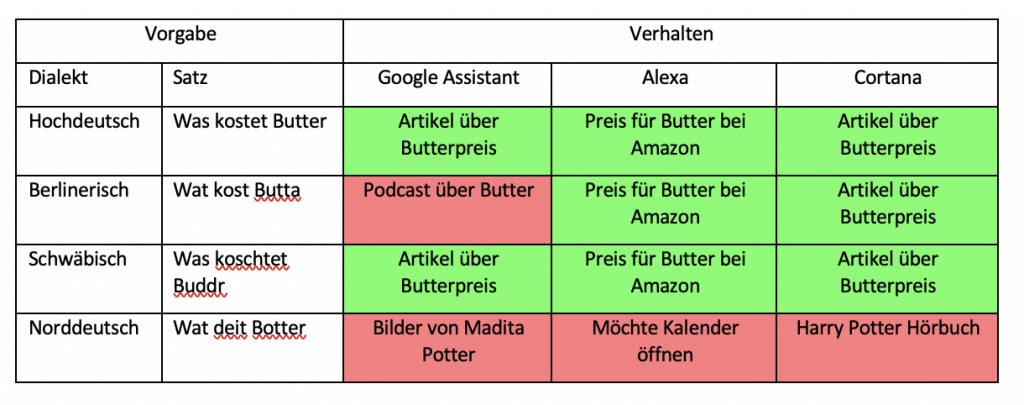
In der ersten Versuchsreihe wurden die gewählten Sprachassistenten nach der Bedeutung einzelner Wörter aus Dialekten gefragt. Hierbei wurde der komplette Satz hochdeutsch gesprochen und nur das zu erfragende Wort in Dialekt. Jeder Satz wurde dabei in jedem Dialekt fünfmal dem Gerät vorgesprochen und jeweils die häufigste Antwort oder Reaktion darauf notiert. Konnte der Sprachassistent laut eigener Aussage die Frage nicht verstehen, wurde dies als falsche Antwort gewertet.
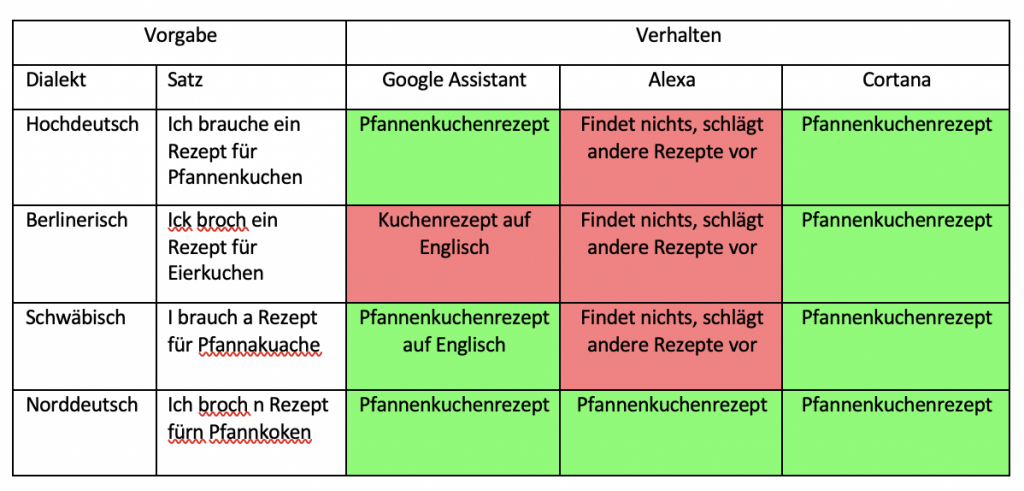
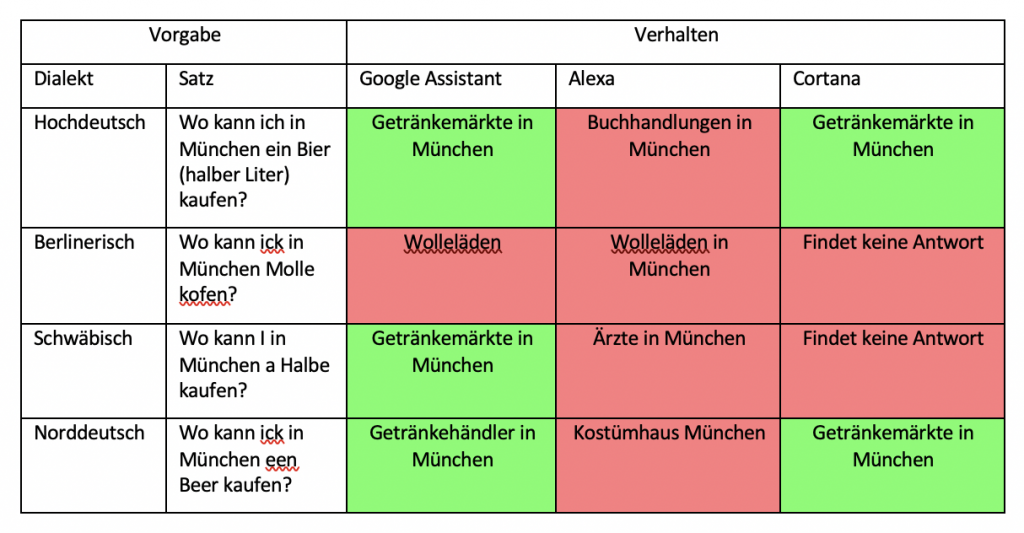
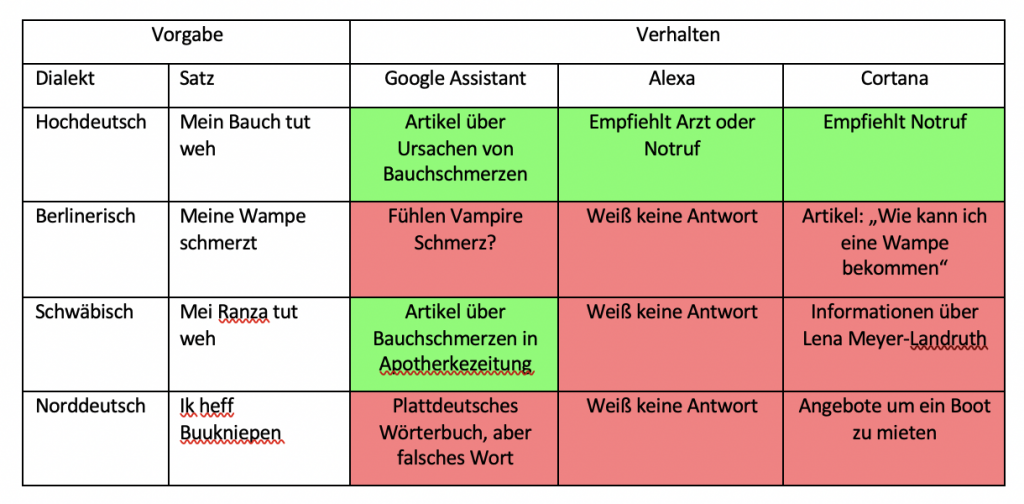
In der zweiten Versuchsreihe wurden ganze Fragesätze in Dialekt gesprochen, wobei verschiedene hochdeutsche Sätze genommen und diese in die Dialekte übersetzt wurden. Diese bestanden aus den häufigsten Suchanfragen des täglichen Lebens, wie beispielsweise, wo welches Geschäft zu finden ist, Rezepte von gängigen Speißen oder wie die Temperatur an einem bestimmten Ort ist. Auch hier bekam jeder Sprachassistent diesen Satz fünfmal in jedem untersuchten Dialekt vorgesprochen, wobei immer die häufigste Antwort gewertet wurde. Wie schon in der ersten Versuchsreihe wurden nicht verstandene Fragen als falsche Antwort gewertet, sofern andere Fehler ausgeschlossen werden konnten.
Ergebnisse
1. Versuchsreihe
Sowohl in der ersten als auch in der zweiten Versuchsreihe zeigen sich sehr unterschiedliche Verhaltensweisen der drei Sprachassistenten. In der ersten Versuchsreihe, bei welcher die Bedeutung einzelner Dialektwörter abgefragt wurden, konnten alle Sprachassistenten mindestens die Hälfte aller Anfragen richtig beantworten. Schlusslicht bildete dabei Amazons Alexa mit 60 % richtigen Antworten. Gerade mit dem schwäbischen Dialekt hatte diese dabei große Probleme. Hier wurde kein einziges Wort richtig definiert. Besser hingegen schnitt Microsofts Cortana ab. Jedoch auch nur mit 65% richtig beantworteten Definition von Wörtern. Auch Cortana hatte hierbei die meisten Schwierigkeiten mit Schwäbisch, aber auch kleinere Probleme mit Norddeutsch und Berlinerisch. Mit 85% richtigen Antworten konnte sich hier der Google Assistant durchsetzen. Google hat fast alle Wörter richtig erkannt und dann eine relevante Antwort ausgegeben. Jedoch war auch hier der schwäbische Dialekt die größte Herausforderung. Bei den richtigen Antworten wurde hier meist die Definition aus Wikipedia oder einem entsprechenden Mundartwörterbuch geliefert.
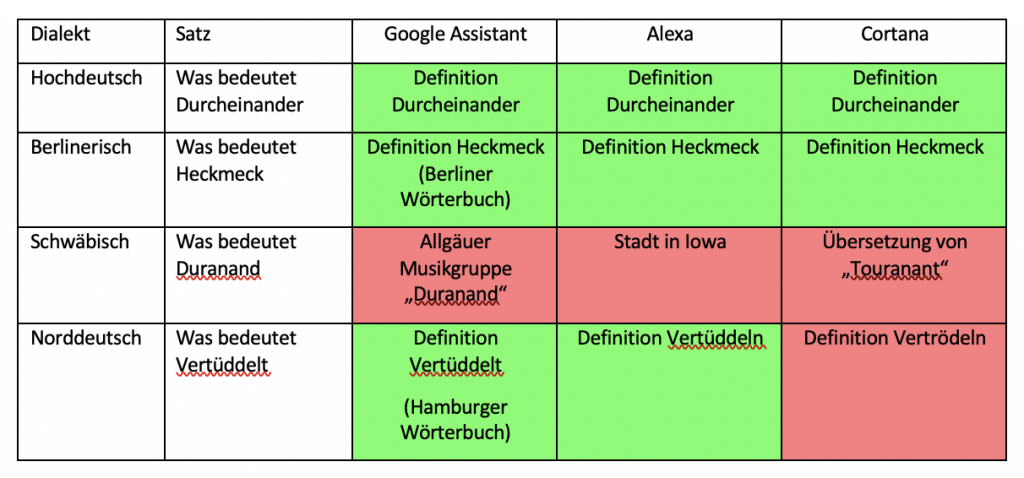
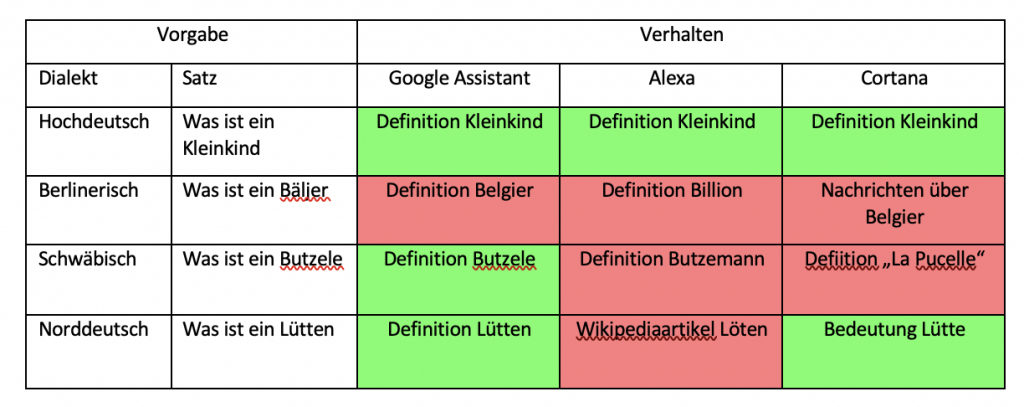
2. Versuchsreihe
In der zweiten Versuchsreihe, in der ganze Dialektsätze erkannt und sinnvoll beantwortet werden sollten, schnitten wiederum alle drei Sprachassistenten eher mittelmäßig ab. Hier wurde oft nur gerade so die Hälfte der Suchanfragen richtig beantwortet. Die wenigsten richtigen Antworten (25%) gab wieder Amazon Alexa. Hier wurden fast durchgehend alle Dialektsätze falsch verstanden. Richtige Antworten bildeten eher die Ausnahme. Oft wurde nicht einmal irgendetwas verstanden, weshalb dann gar keine Antwort gegeben wurde. Besser schnitten hier Google Assistant, mit 54% richtigen Antworten, und Cortana, mit 58% richtigen Antworten, ab. Diesen machte vor allem der norddeutsche Dialekt Probleme, jedoch auch auf Berlinerisch und teilweise auf den schwäbischen Dialekt keine vernünftigen Antworten gefunden wurden. Für die richtigen Antworten wurde hier durch die Sprachassistenten auf eine Vielzahl von Quellen zurückgegriffen, welche auch je nach Unternehmen unterschiedlich waren.
Die größten Schwierigkeiten hatten alle getesteten Sprachassistenten mit dem Schwäbischen. Hier lagen in beiden Testreihen die Sprachassistenten nur zu 42% richtig. Wurden die Sprachassistenten auf Hochdeutsch gefragt, waren dies immerhin durchschnittlich 87% richtige Antworten. Ursache hierfür könnte der unterschiedliche Wortschatz des Schwäbischen und des Hochdeutschen sein. Außerdem ist das Schwäbische durch viele SCH-Laute gekennzeichnet, also ein sehr nuschelnder Dialekt. Dies könnte die Abgrenzung der Wörter für die Analyseprogramme erschweren und sich somit auf die richtige Antworterstellung auswirken.
Des Weiteren wurde von einem der am weitesten verbreiteten Sprachassistenten, Amazons Alexa, eigentlich bessere Ergebnisse erwartet. Doch dieser Sprachassistent belegte in beiden Versuchsreihen jeweils den letzten Platz. Oft wurde hier scheinbar nicht mal die Frage nur falsch verstanden, sondern gar kein Sinn durch den Sprachassistenten hinter dieser erkannt. Dies führte dann zu einem ernüchterndem „Darauf habe ich leider keine Antwort“. Ebenso merkte man deutlich, dass Alexa und Cortana auf dieselbe Suchmaschine, Bing von Microsoft, zugreifen, da hier oft auf Fragen eine komplett andere Antwort gegeben wurde. Oft stellte sich auch die Frage, ob der Sprachassistent die Frage nicht richtig verstanden, oder einfach die falsche Antwort herausgesucht hat. Dies ist jedoch meist nicht überprüfbar, da Geräte ohne Display nicht erkennen lassen, welche Wörter genau aus dem Sprachsignal herausgearbeitet wurden.
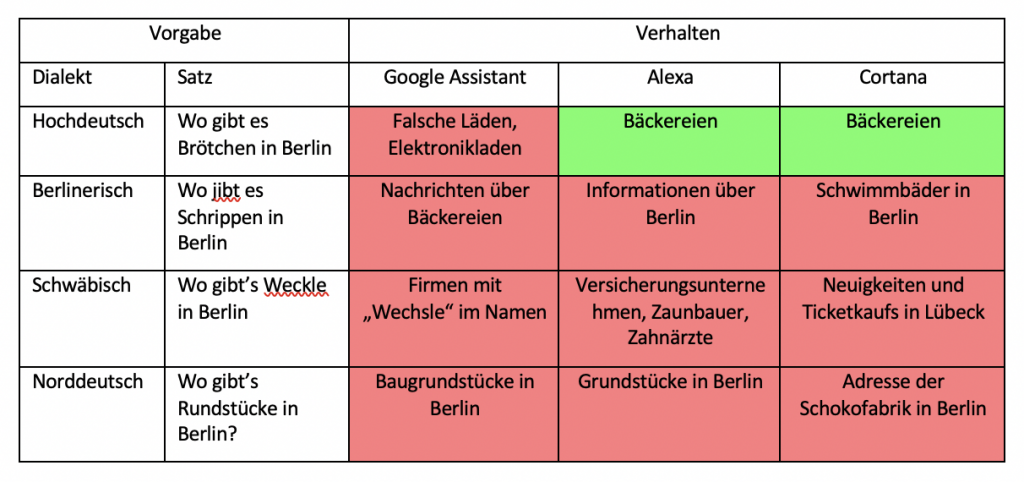
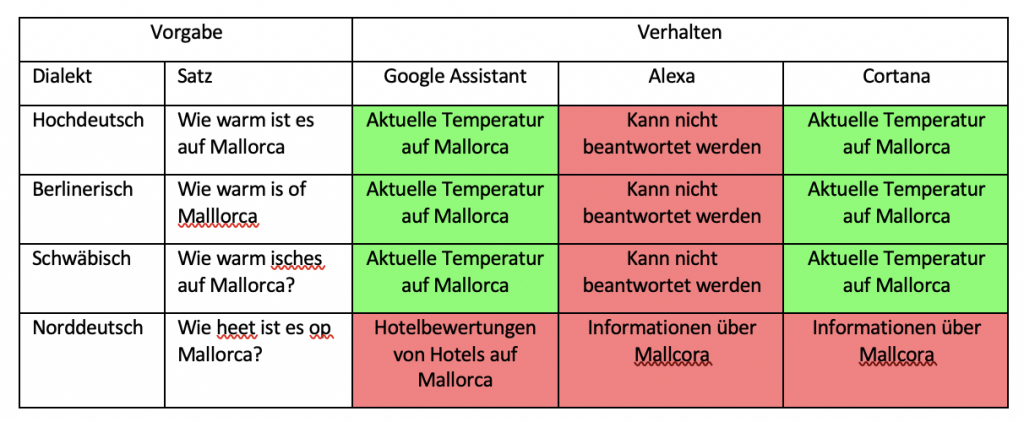
Gesamtergebnisse KOMPAKT

Erfolge
Also Erfolg kann man allerdings sehen, dass Sprachassistenten heutzutage schon sehr gute Ergebnisse liefern können. Nicht nur im Hochdeutschen waren diese meist mit relevanten Antworten ausgestattet, sondern auch kompliziertere Dialektsätze oder Wörter wurden teilweise sehr gut verstanden und beantwortet. Dabei zeigte sich auch die Stärke der Suchmaschine Google. Während Alexa und Cortana bei Fragen auf die Bing-Suche von Microsoft zurückgreifen, und damit oft skurrile Antworten liefern, liefert Google deutlich bessere Antworten.
Literaturverzeichnis
[1] B. Pfister, T. Kaufmann: „Sprachverarbeitung- Grundlagen und Methoden
der Sprachsynthese und Spracherkennung“, Springer Vieweg, 2017.




